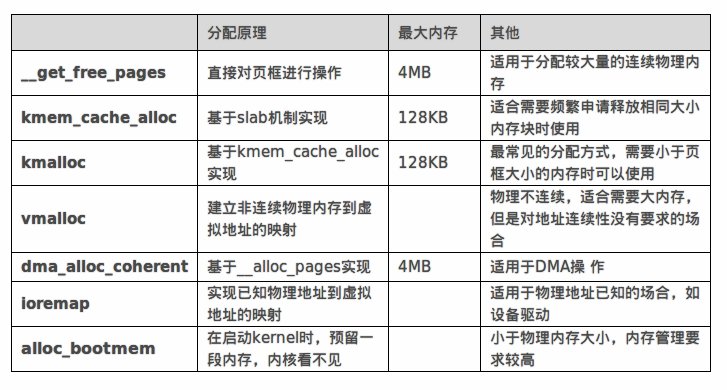
空间页面
linux 内存分配图
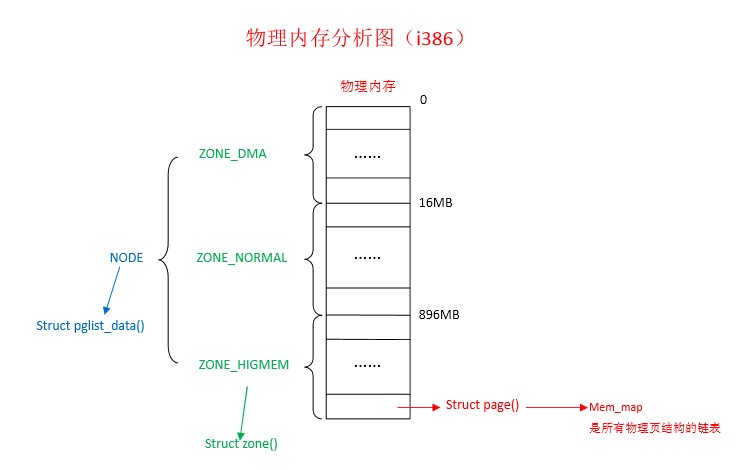
linux 内存的映射
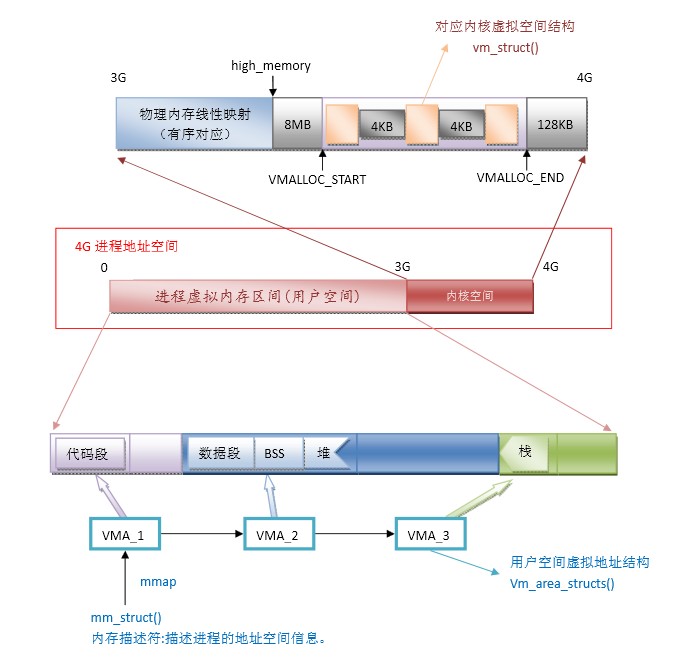 linux 内存分配函数关系
linux 内存分配函数关系
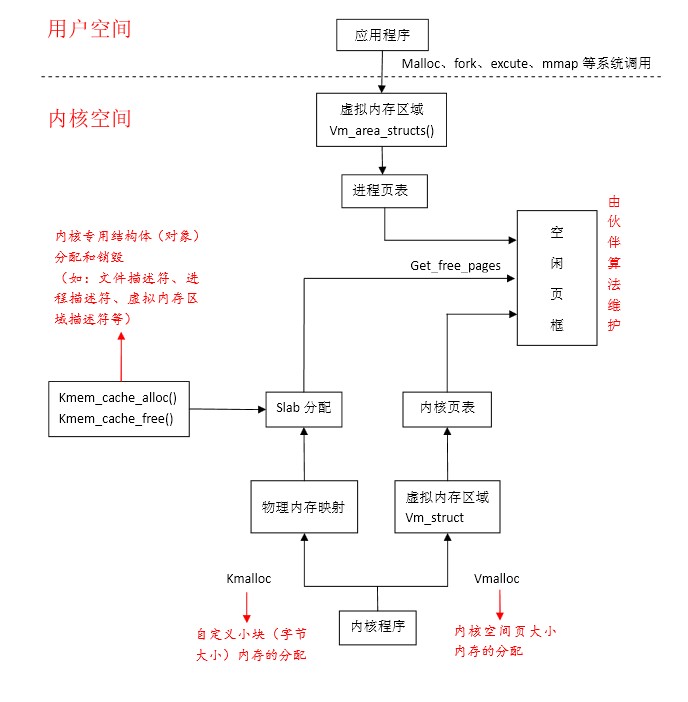
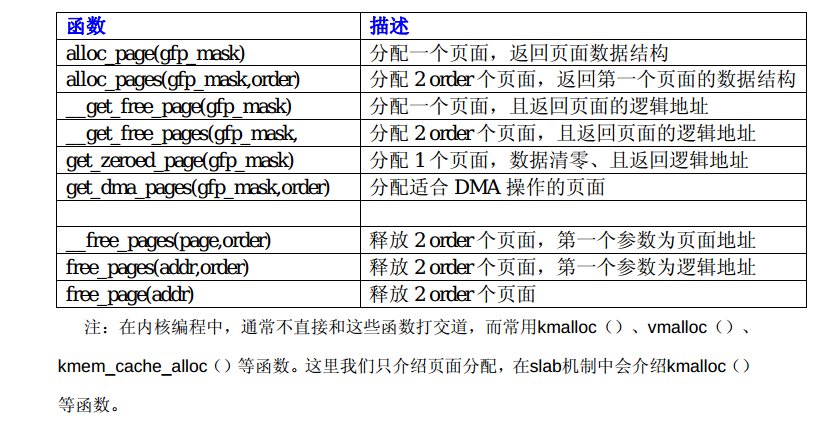
内存管理函数
一.伙伴系统
在实际应用中,经常需要分配一组连续的页框,而频繁地申请和释放不同大小的连续页框,必然导致在已分配页框的内存块中分散了许多小块的 空闲页框。这样,即使这些页框是空闲的,其他需要分配连续页框的应用也很难得到满足。
为了避免出现这种情况,Linux内核中引入了伙伴系统算法(buddy system)。把所有的空闲页框分组为11个 块链表,每个块链表分别包含大小为1,2,4,8,16,32,64,128,256,512和1024个连续页框的页框块。最大可以申请1024个连 续页框,对应4MB大小的连续内存。每个页框块的第一个页框的物理地址是该块大小的整数倍。
假设要申请一个256个页框的块,先从256个页框的链表中查找空闲块,如果没有,就去512个 页框的链表中找,找到了则将页框块分为2个256个 页框的块,一个分配给应用,另外一个移到256个页框的链表中。如果512个页框的链表中仍没有空闲块,继续向1024个页 框的链表查找,如果仍然没有,则返回错误。
页框块在释放时,会主动将两个连续的页框块合并为一个较大的页框块。
二.slab分配器
slab分配器源于 Solaris 2.4 的 分配算法,工作于物理内存页框分配器之上,管理特定大小对象的缓存,进行快速而高效的内存分配。
slab分配器为每种使用的内核对象建立单独的缓冲区。Linux 内核已经采用了伙伴系统管理物理内存页框,因此 slab分配器直接工作于伙伴系 统之上。每种缓冲区由多个 slab 组成,每个 slab就是一组连续的物理内存页框,被划分成了固定数目的对象。根据对象大小的不同,缺省情况下一个 slab 最多可以由 1024个页框构成。出于对齐 等其它方面的要求,slab 中分配给对象的内存可能大于用户要求的对象实际大小,这会造成一定的 内存浪费。
三.内存分配函数
1.__get_free_pages
unsigned long __get_free_pages(gfp_t gfp_mask, unsigned int order)
__get_free_pages函数是最原始的内存分配方式,直接从伙伴系统中获取原始页框,返回值为第一个页框的起始地址。 __get_free_pages在实现上只是封装了alloc_pages函 数,从代码分析,alloc_pages函数会分配长度为1«order的 连续页框块。order参数的最大值由include/linux/Mmzone.h 文 件中的MAX_ORDER宏决定,在默认的2.6.18内 核版本中,该宏定义为10。也就是说在理论上__get_free_pages函 数一次最多能申请1«10 * 4KB也就是4MB的 连续物理内存。但是在实际应用中,很可能因为不存在这么大量的连续空闲页框而导致分配失败。在测试中,order为10时分配成功,order为11则返回错误。
2.kmen_cache_alloc
struct kmem_cache *kmem_cache_create(const char *name, size_t size,
size_t align, unsigned long flags,
void (*ctor)(void*, struct kmem_cache *, unsigned long),
void (*dtor)(void*, struct kmem_cache *, unsigned long))
void *kmem_cache_alloc(struct kmem_cache *c, gfp_t flags)kmem_cache_create/ kmem_cache_alloc是基于slab分配器的一种内存分配方式,适用于反复分配释放同一大小内存块的场合。首先用 kmem_cache_create创建一个高速缓存区域,然后用kmem_cache_alloc从 该高速缓存区域中获取新的内存块。 kmem_cache_alloc一次能分配的最大内存由mm/slab.c文件中的MAX_OBJ_ORDER宏 定义,在默认的2.6.18内核版本中,该宏定义为5, 于是一次最多能申请1«5 * 4KB也就是128KB的 连续物理内存。分析内核源码发现,kmem_cache_create函数的size参数大于128KB时会调用BUG()。测试结果验证了分析结果,用kmem_cache_create分 配超过128KB的内存
3.kmalloc
void *kmalloc(size_t size, gfp_t flags)
kmalloc是内核中最常用的一种内存分配方式,它通过调用kmem_cache_alloc函 数来实现。kmalloc一次最多能申请的内存大小由include/linux/Kmalloc_size.h的 内容来决定,在默认的2.6.18内核版本中,kmalloc一 次最多能申请大小为131702B也就是128KB字 节的连续物理内存。测试结果表明,如果试图用kmalloc函数分配大于128KB的内存,编译不能通过。
给 kmalloc 的第一个参数是要分配的块的大小. 第 2 个参数, 分配标志, 非常有趣, 因为它以几个方式控制 kmalloc 的行为.
最一般使用的标志, GFP_KERNEL, 意思是这个分配((内部最终通过调用 _get_free_pages 来进行, 它是 GFP 前缀的来源) 代表运行在内核空间的进程而进行的. 换句话说, 这意味着调用函数是代表一个进程在执行一个系统调用. 使用 GFP_KENRL 意味着 kmalloc 能够使当前进程在少内存的情况下睡眠来等待一页. 一个使用 GFP_KERNEL 来分配内存的函数必须, 因此, 是可重入的并且不能在原子上下文中运行. 当当前进程睡眠, 内核采取正确的动作来定位一些空闲内存, 或者通过刷新缓存到磁盘或者交换出去一个用户进程的内存.
GFP_KERNEL 不一直是使用的正确分配标志; 有时 kmalloc 从一个进程的上下文的外部调用. 例如, 这类的调用可能发生在中断处理, tasklet, 和内核定时器中. 在这个情况下, 当前进程不应当被置为睡眠, 并且驱动应当使用一个 GFP_ATOMIC 标志来代替. 内核正常地试图保持一些空闲页以便来满足原子的分配. 当使用 GFP_ATOMIC 时, kmalloc 能够使用甚至最后一个空闲页. 如果这最后一个空闲页不存在, 但是, 分配失败.
其他用来代替或者增添 GFP_KERNEL 和 GFP_ATOMIC 的标志, 尽管它们 2 个涵盖大部分设备驱动的需要. 所有的标志定义在 <linux/gfp.h>, 并且每个标志用一个双下划线做前缀, 例如 __GFP_DMA. 另外, 有符号代表常常使用的标志组合; 这些缺乏前缀并且有时被称为分配优先级. 后者包括:
GFP_ATOMIC 用来从中断处理和进程上下文之外的其他代码中分配内存. 从不睡眠.
GFP_KERNEL 内核内存的正常分配. 可能睡眠.
GFP_USER 用来为用户空间页来分配内存; 它可能睡眠.
GFP_HIGHUSER 如同 GFP_USER, 但是从高端内存分配, 如果有. 高端内存在下一个子节描述.
GFP_NOIO GFP_NOFS 这个标志功能如同 GFP_KERNEL, 但是它们增加限制到内核能做的来满足请求. 一个 GFP_NOFS 分配不允许进行任何文件系统调用, 而 GFP_NOIO 根本不允许任何 I/O 初始化. 它们主要地用在文件系统和虚拟内存代码, 那里允许一个分配睡眠, 但是递归的文件系统调用会是一个坏注意.
上面列出的这些分配标志可以是下列标志的相或来作为参数, 这些标志改变这些分配如何进行:
__GFP_DMA 这个标志要求分配在能够 DMA 的内存区. 确切的含义是平台依赖的并且在下面章节来解释.
__GFP_HIGHMEM 这个标志指示分配的内存可以位于高端内存.
__GFP_COLD 正常地, 内存分配器尽力返回”缓冲热”的页 – 可能在处理器缓冲中找到的页. 相反, 这个标志请求一个”冷”页, 它在一段时间没被使用. 它对分配页作 DMA 读是有用的, 此时在处理器缓冲中出现是无用的. 一个完整的对如何分配 DMA 缓存的讨论看”直接内存存取”一节在第 1 章.
__GFP_NOWARN 这个很少用到的标志阻止内核来发出警告(使用 printk ), 当一个分配无法满足.
__GFP_HIGH 这个标志标识了一个高优先级请求, 它被允许来消耗甚至被内核保留给紧急状况的最后的内存页.
__GFP_REPEAT __GFP_NOFAIL __GFP_NORETRY 这些标志修改分配器如何动作, 当它有困难满足一个分配. __GFP_REPEAT 意思是” 更尽力些尝试” 通过重复尝试 – 但是分配可能仍然失败. __GFP_NOFAIL 标志告诉分配器不要失败; 它尽最大努力来满足要求. 使用 __GFP_NOFAIL 是强烈不推荐的; 可能从不会有有效的理由在一个设备驱动中使用它. 最后, __GFP_NORETRY 告知分配器立即放弃如果得不到请求的内存.
4.vmalloc
void *vmalloc(unsigned long size)
前面几种内存分配方式都是物理连续的,能保证较低的平均访问时间。但是在某些场合中,对内存区的请求不是很频繁,较高的内存访问时间也 可以接受,这是就可以分配一段线性连续,物理不连续的地址,带来的好处是一次可以分配较大块的内存。图3-1表 示的是vmalloc分配的内存使用的地址范围。vmalloc对 一次能分配的内存大小没有明确限制。出于性能考虑,应谨慎使用vmalloc函数。在测试过程中, 最大能一次分配1GB的空间。
5.dma_alloc_coherent
void *dma_alloc_coherent(struct device *dev, size_t size,
ma_addr_t *dma_handle, gfp_t gfp)
DMA是一种硬件机制,允许外围设备和主存之间直接传输IO数据,而不需要CPU的参与,使用DMA机制能大幅提高与设备通信的 吞吐量。DMA操作中,涉及到CPU高速缓 存和对应的内存数据一致性的问题,必须保证两者的数据一致,在x86_64体系结构中,硬件已经很 好的解决了这个问题, dma_alloc_coherent和__get_free_pages函数实现差别不大,前者实际是调用__alloc_pages函 数来分配内存,因此一次分配内存的大小限制和后者一样。__get_free_pages分配的内 存同样可以用于DMA操作。测试结果证明,dma_alloc_coherent函 数一次能分配的最大内存也为4M.
6.ioremap
void * ioremap (unsigned long offset, unsigned long size)
ioremap是一种更直接的内存“分配”方式,使用时直接指定物理起始地址和需要分配内存的大小,然后将该段 物理地址映射到内核地址空间。ioremap用到的物理地址空间都是事先确定的,和上面的几种内存 分配方式并不太一样,并不是分配一段新的物理内存。ioremap多用于设备驱动,可以让CPU直接访问外部设备的IO空间。ioremap能映射的内存 由原有的物理内存空间决定,所以没有进行测试。
7.boot Memory
7.1.在内核引导时分配内存
void* alloc_bootmem(unsigned long size)
可以在Linux内核引导过程中绕过伙伴系统来分配大块内存。使用方法是在Linux内核引导时,调用mem_init函数之前 用alloc_bootmem函数申请指定大小的内存。如果需要在其他地方调用这块内存,可以将alloc_bootmem返回的内存首地址通过 EXPORT_SYMBOL导 出,然后就可以使用这块内存了。这种内存分配方式的缺点是,申请内存的代码必须在链接到内核中的代码里才能使用,因此必须重新编译内核,而且内存管理系统 看不到这部分内存,需要用户自行管理。测试结果表明,重新编译内核后重启,能够访问引导时分配的内存块。
7.2.通过内核引导参数预留顶部内存
在Linux内核引导时,传入参数“mem=size”保留顶部的内存区间。比如系统有256MB内 存,参数“mem=248M”会预留顶部的8MB内存,进入系统后可以调用ioremap(0xF800000,0x800000)来申请这段内存。